WinRDBI is a teaching tool for use in the introductory database course at Arizona State University. It allows the user to interactively experiment with Relational Algebra, Domain Relational Calculus, DRC By-Name, Tuple Relational Calculus, and Structured Query Language expressions. WinRDBI interacts with a Prolog engine that performs the actual database manipulations.
WinRDBI is based on RDBI, which was written over a number of years by students as independent study projects. RDBI was written in Quintus Prolog and ran under UNIX or VMS. Using RDBI, students interacted with a command-line oriented user interface. This required students to use on-campus facilities, either on-site or via dial-up, to access the program. Additionally, RDBI could only be used on systems that were licensed to run Quintus Prolog. Further information and a description of how to use the original RDBI tool is described in [2].
Later, Version 1.0 of WinRDBI was written. Its interface and use is documented in [3]. In addition to providing a simpler, more intuitive Graphical User-Interface (GUI) interface with which students could interact, WinRDBI gave students who have IBM compatible computers at home the ability to run RDBI on their own computers. To help accomplish that goal, WinRDBI used the Amzi! Prolog Logic Server rather than Quintus Prolog. The Amzi! product was chosen because it has no runtime license restrictions for non-commercial use.
Version 1.0 of WinRDBI was used for several semesters at ASU. Over that time, several shortcomings were found. For example, the user could interact with only one query at a time. Once a query was completed, it had to be saved to a file before a new query could be started. The query was then no longer visible from within the user interface. If the user wanted to review a previously completed query, a separate editor or viewer program had to be used. This made it very difficult to construct the answer to a question that involved multiple sub-queries. Another related shortcoming was that any comments that were entered into the user interface as part of a query were lost when the query was saved to disk.
Relative to the database, Version 1.0 provided very minimal editing capabilities. Tuples could be inserted and deleted, but not edited. In order to change a field in a tuple, the entire tuple had to be deleted and re-entered. The only other option was to save the database as a text file of Prolog facts, call up a text editor to change the appropriate data, then reload the database into the user interface. Further, any relations that were materialized as part of a query became part of the database. After a query had been executed, it was not possible to save the original database without first deleting these extra relations.
These limitations gave rise to the WinRDBI 2.0 version as a complete redesign of the user interface of Version 1.0. Version 2.0 is written in Java and uses the Java Foundation Classes (JFC), or Swing, to provide the user interface. Version 2.0 still interacts with the Amzi! Prolog Logic Server to perform the database operations, but the user interface, described in the next section, is entirely different.
A new language, DRC By-Name, was introduced in WinRDBI 3.0. DRC By-Name has the same computational power as Domain Relational Calculus. The advantage of this language is the ability to reference an attribute by name rather than by position.
WinRDBI 4.0, allows for the storage of the database in XML. In addition to the integration of XML into WinRDBI, several other features were added to improve the application's functionality and usability. These enhacements included: adding the capability to save query results, and adding a cut-copy-paste context menu to the query and schema panes.
WinRDBI 5.0 is compiled for Java 7 and installers are provided for both 32-bit and 64-bit architectures. The program functionality has also been improved to add features to the editor, such as undo, redo, matching braces, and preferences for font size.
WinRDBI 2020 is compiled using OpenJDK 14.0.1 for 64-bit architecture and released as a zip package. Additional functionality includes the ability to sort data by a column. Selecting the column again reverses the order.
WinRDBI 2021 adds the capability to export and import csv files. Export creates a collection of csv files for a WinRDBI database instance: one for each table. Import imports a csv file with a header line having the syntax:
field1/type1, field2/type2, ..., fieldn/typen
where a field name must begin with a lowercase letter and must not contain special characters, and a type is either char for a character string or numeric. WinRDBI's export uses this syntax as well for the header line of the exported csv file.
WinRDBI is designed as a Multiple Document Interface (MDI) application. In the general sense, a MDI application allows you to have more than one "document" open at a time, for example, more than one word-processor document or spreadsheet. In the case of WinRDBI, a document may be a database or a query file. While WinRDBI allows you to have multiple query files open simultaneously, only one database file may be open at a time.
The image below shows the initial WinRDBI screen. At this point, you may open an existing query or database or create new ones using the File menu or the toolbar.
In the following sections, these components will be described in some detail.
There are two additional components which will be mentioned regularly. The first is called a SchemaPane. A SchemaPane is an internal window on the main screen that contains the database schema and instance against which the queries will be executed. The figure below shows a SchemaPane.
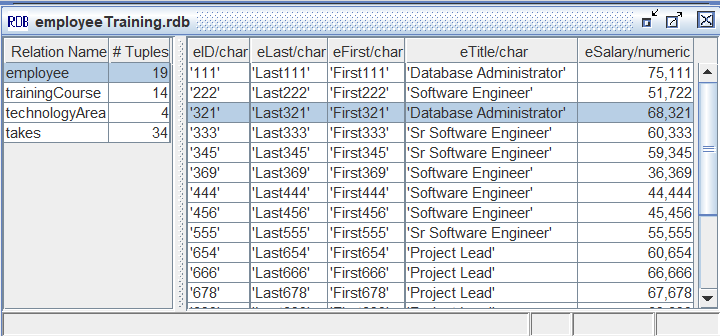
Notice that the pane is vertically divided in two. On the left is a list of the relation names and the number of tuples in the relation. On the right is a list of the tuples in the relation. In a SchemaPane, you can add, delete, and edit relations and tuples. There may be only one SchemaPane open at a time. Additionally, associated with the SchemaPane is a Cut-Copy-Paste pop-up menu which can be activated while editing a tuple cell through a double mouse click.
The second component of the WinRDBI user interface is a QueryPane to enter queries and display the results of the queries. A QueryPane is shown below.
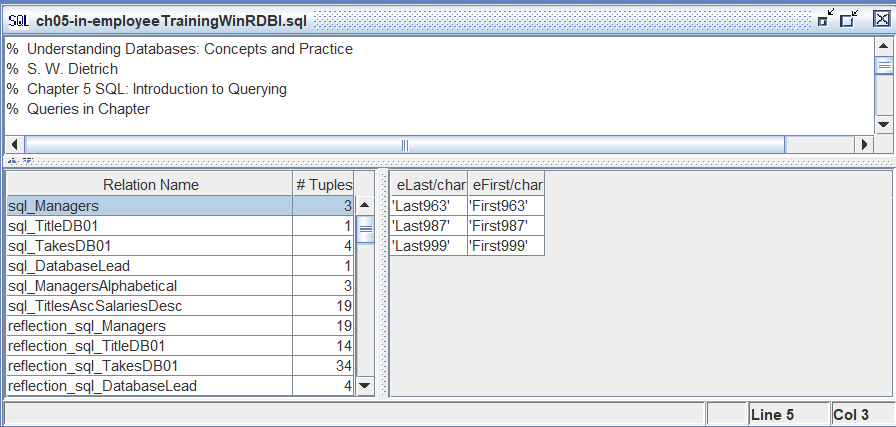
A QueryPane is divided into three sections. The top section is a basic text editor for entering queries in one of the five query languages. The top section also contains a Cut-Copy-Paste context menu to allow for easy editing, which. can be activated through a right mouse click. The bottom section, which is similar to a SchemaPane, displays the results of the queries. Note that the relations and tuples representing query results cannot be edited, however, the results can be saved via the File/Save Query Results menu item when the QueryPane is active. The results can also be sorted by clicking on one of the field names.
This section describes the available menu items in WinRDBI.
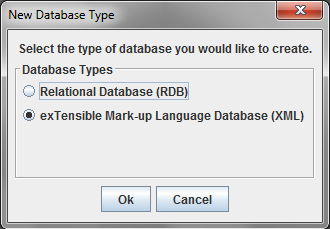
The New Database menu item allows you to create a new database. When you select this option, the following dialog will be displayed allowing you to choose what type of database storage format you would like to use. The two database storage options are the RDB file format or the XML file format. RDB is a structured, flat text file format that contains schema information interspersed with actual tuple data and uses special delimiters to mark parts of schema information and single quotes to differentiate between numeric and char attribute data values. The XML file format is a self-describing document that includeds DTD and data sections.
Once you have selected the appropriate database storage format, you will be given an empty SchemaPane, as shown below.
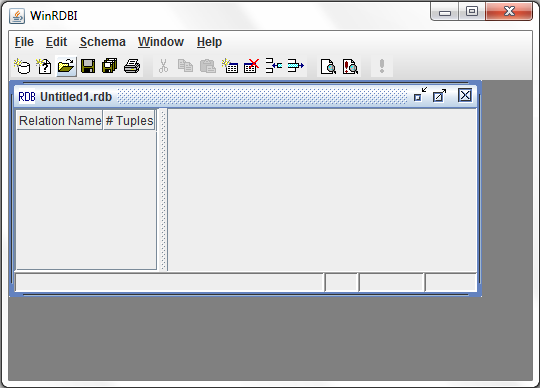
At this point, you can use various toolbar icons or items on the Schema menu to add relations and tuples to your database.
When you select the New Query item, the dialog below will be displayed, asking you what kind of queries you want to enter: Relational Algebra, Domain Relational Calculus, Tuple Relational Calculus, Structured Query Language or DRC By-Name. The default is Relational Algebra. You must select one of the options to proceed.
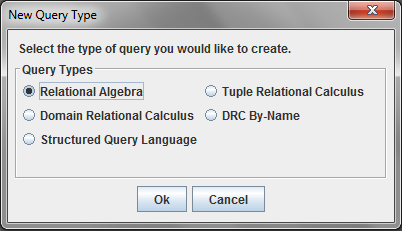
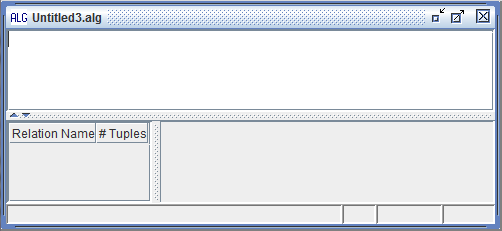
Once you have selected the appropriate type of queries, you will be given an empty QueryPane, as shown below.
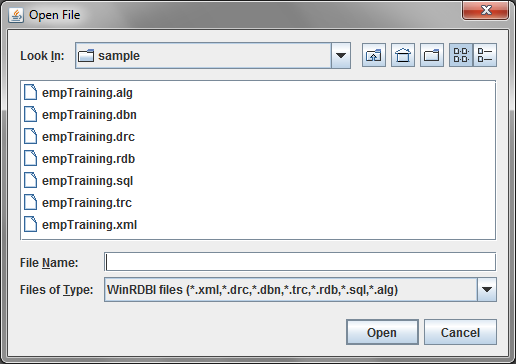
If you choose "Open..." from the File menu, you will be shown the following dialog from which you can choose a query or database file to open.
Choosing this item will close the currently active window. If there are unsaved changes, you will be offered a chance to save the changes.
Save the contents of the currently active QueryPane or SchemaPane.
Save the query execution results in an RDB or XML database file.
Save the contents of all open panes.
The Save As item allows you to save the active file under a new name. If you choose this item, you will see a dialog box similar to the one below.
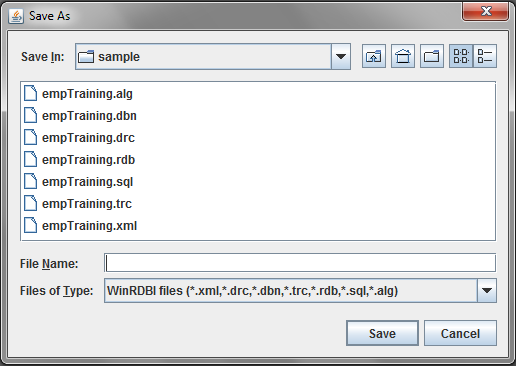
You would enter a new file name in the field labeled "File name:". In the figure above, this is the field that contains "empTraining.alg". If you enter the name of a file that already exists, you will be asked if you want to overwrite the existing file. If you answer no, you will be given the opportunity to enter another file name. If you indicate that you do want to overwrite the existing file, then the save action will proceed normally.
The Import item allows you to import a csv file as a relation to the open Schema Pane. If no Schema Pane is selected, a new Schema Pane will be created where the table name is the name of the csv file with its corresponding data. Note that the csv file to be imported must have a header line having the syntax: field1/type1, field2/type2, ..., fieldn/typen where a field name must begin with a lowercase letter and must not contain special characters, and a type is either char for a character string or numeric.
The Export item allows you to save the active database file using a csv format by generating a csv file for each table. A dialog box similar to the Save As allows the choice of the directory in which to store the resulting csv files and to provide the prefix name for the csv files. For example, if the prefix entered is et, each table will be exported as et_tablename.
Choosing the Print item will allow you to print queries, query results, or relations from the database based on the active pane. If one or more relations are selected in the results or the database, you will be given the option to print only the selected relations or all relations. Multiple non-adjacent relations may be selected by holding down the control key on the keyboard while clicking with the left mouse button. An entire region may be selected by left-clicking on the first relation, then holding down the shift key while left-clicking another relation. Control-shift-left-click can be used to select non-adjacent regions.
Choosing "Exit" from the file menu will close all open windows and exit the program. If there are unsaved changes, you will be given the opportunity to save them.
The Edit Menu contains the normal clipboard operations Cut, Copy, and Paste, along with Search and Replace operations. The clipboard operations are only available when you are editing queries or when you are editing a specific field in a tuple. The Preferences menu is also accessible from here.
The Undo item allows you to undo changes made to the text from a query editor. Undo will undo one character at a time.
The Redo item allows you to redo changes that were undone through the use of Undo. Redo will redo one character at a time.
The Cut item allows you to copy selected text from a query editor or field editor to the clipboard. The selected text is then deleted from the editor.
The Copy item performs essentially the same function as the Cut item, but the selected text is not deleted from the editor.
Choosing the Paste item copies text from the clipboard to the query or field editor.
Select the Find item to search for text in the currently active Pane. The pane can be either a QueryPane or a SchemaPane. When you select the Find item, you will see the following dialog box:
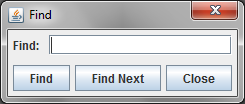
Enter the text you wish to find in the field. To initiate the search, click on the "Find" button, or press enter. If the text is found, it will be selected. If it is not found, a dialog box will be displayed indicating that no matching text was found. To find subsequent occurrences, click on the "Find Next" button. Click on the "Close" button to dismiss the dialog box.
The Replace item allows you to search the active Pane for a string and replace it with another string. Like the Find item, Replace can be used in either a QueryPane or a SchemaPane. Note, however, that the Replace option does not work in the results portion of a QueryPane, as the result table is not editable. The dialog box looks like
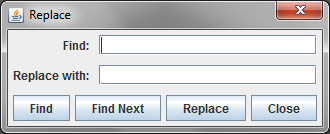
Like the Find dialog, enter the text for which you wish to search in the field labeled "Find:". Then enter the replacement text in the field labeled "Replace with:" and click the "Find" button. If the text is found, it will be highlighted. To replace the text, click on the "Replace" button. Clicking on "Replace" will cause the highlighted text to be replaced with the replacement text and will automatically search for the next occurrence of the search string. If you don't wish to replace an occurrence, just click on "Find Next". Of course, click the "Close" button to dismiss the dialog.
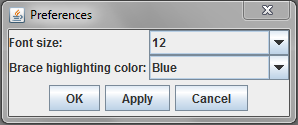
The Preferences menu allows you to change the font size for WinRDBI and the color used to highlight matching braces in the QueryPane.
Choose the Add Relation item to add a new relation to a database. This option is only available when a SchemaPane is active. When you choose this item, the following dialog will be displayed
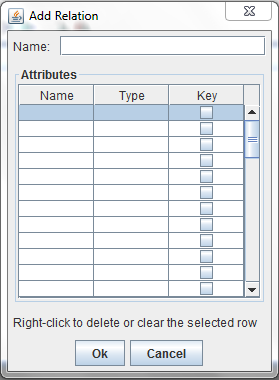
The relation name should be entered in the field labeled "Name:", while the attributes should be entered in the table below. Note that relation and attribute names must be identifiers starting with a lower case letter. If an attribute is part of the key, put a check in the "Key" column by clicking on the appropriate box. Here's a more complete example.
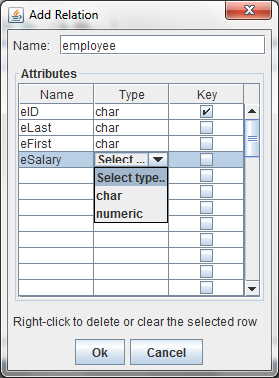
Note that the attribute named "eID" is the key attribute. You can create a composite key by checking more that one box. The "Type" column allows only two entries, char and numeric, which are selected from the drop-down list.
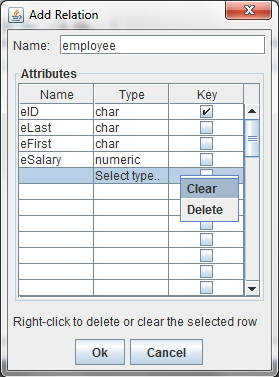
If you make a mistake in creating an attribute, you can delete or clear the attribute from the Add Relation dialog. Select the row and right-click. This will bring up a menu with options to Clear or Delete. Clear will reset the row to the default, blank row. Delete will remove the row entirely, which is useful for removing attributes from the beginning or middle of the table.
When a QueryPane is active, this item is available. It allows you to copy the selected relation from the query results to the SchemaPane. In this way, you can save and/or edit the results of a query. This option is only available when a QueryPane is active.
The Delete Relation item deletes the selected relations from the database. This option is only available when a SchemaPane is active.
Select the Edit Relation option from the Schema menu to bring up a dialog box which will allow you to edit the name and attributes of a relation. This dialog box is the same as the "Add Dialog" box, with the restriction that you can only change the name of the relation or the names of the attributes. You may also activate the dialog box by double-clicking the left mouse button on the relation name. This option is only available when a SchemaPane is active.
The Add Tuple item adds one or more tuples to the currently selected relation. If there are multiple tuples selected, then the number of tuples added will be equal to the number of tuples selected. The new tuples will always be added to the end of the table. This option is only available when a SchemaPane is active.
Selecting the Delete Tuple item causes the selected tuples to be deleted. This option is only available when a SchemaPane is active.
Choose the Insert Tuple item to insert one of more tuples into the currently selected relation. If there are multiple tuples selected, then the number of tuples inserted will be equal to the number of tuples selected. The new tuples will be inserted above the first selected tuple. This option is only available when a SchemaPane is active.
Choose the Check Keys item to verify the primary key integrity of a selected relation. A pop up window will identify the primary key attributes and confirm the primary key is valid. If there are duplicate primary key values, a warning will appear. In the event that the relation does not have a primary key specified, this action prompts for the selection of a primary key.
Execute the queries in the currently active QueryPane. This item is available only when a QueryPane is active and a database is loaded. The results will be shows in the table in the bottom half of the QueryPane.
The Window menu will contain the names of all open panes. If a pane is hidden, you can bring it to the front by selecting the corresponding item in the Window menu.
In addition to an item corresponding to each pane, the Window menu contains an Arrange item. The Arrange item arranges all open panes by tiling the QueryPanes in the upper 3/4 of the main screen and puts the SchemaPane, if one is open, in the lower 1/4 of the main screen. The end result will look something like the figure below.
The Help menu contains options to view the documentation for WinRDBI and general information about WinRDBI application.
The User Guide is online at http://winrdbi.asu.edu. You can also open the html file for the User Guide locally, which is distributed in the doc folder in the zip file.
Displays the following dialog, which indicates the copyright and existence of the license agreement and contains WinRDBI's web address.

The following table describes the action performed by each toolbar icon and lists the equivalent menu operation. The notation A ® B means to select item B from menu A. More specifically, File ® Open means to select the Open item from the File menu.
|
Icons |
Description | Menu Equivalent |
Keyboard Shortcut |
|
|
Create a new, empty SchemaPane. | File ® New Database | Ctrl+D |
|
|
Create a new, empty QueryPane. | File ® New Query | Ctrl+Q |
|
|
Open an existing file. | File ® Open | Ctrl+O |
|
|
Save the contents of the currently active pane. | File ® Save | Ctrl+S |
|
|
Save the contents of all open panes. | File ® Save All | |
|
|
Print the currently active pane. | File ® Print | Ctrl+P |
|
|
Cut the selected text to the clipboard. | Edit ® Cut | Ctrl+X |
|
|
Copy the selected text to the clipboard. | Edit ® Copy | Ctrl+C |
|
|
Paste the clipboard contents to the current location. | Edit ® Paste | Ctrl+V |
|
|
Add a relation to the current database. | Schema ® Add Relation | |
|
|
Delete the selected relations from the current database. | Schema ® Delete Relation | |
|
|
Check the primary key for the selected tabel. | Schema ® Check Keys | |
|
|
Insert one or more tuples into the current relation. | Schema ® Insert Tuple | |
|
|
Delete the selected tuples from the current relation. | Schema ® Delete Tuple | |
|
|
Search for text in the active QueryPane or SchemaPane. | Edit ® Find | Ctrl+F |
|
|
Replace text in the active QueryPane or SchemaPane. | Edit ® Replace | Ctrl+R |
|
|
Execute the queries in the active QueryPane. | Schema ® Execute Queries | Ctrl+E |
This section provides an overview of the assumptions for each language provided by WinRDBI, including its BNF. Detailed language examples are provided in [1] and on the WinRDBI Web [4]. The WinRDBI distribution includes the database and queries for the EMPLOYEE TRAINING enterprise [1].
The WinRDBI languages are case sensitive. Relation and attribute names must be identifiers starting with a lowercase letter. Constants in all languages and in the database are either (single) quoted strings or numeric constants. Variables are identifiers that start with an uppercase letter.
The grammars described in this section use the following conventions: terminal symbols are in boldface, non-terminal symbols are in angle brackets (<>), patterns are in italics, and braces ({}) indicate optional items. The following grammar provides the syntax for creating intermediate tables with optional renaming of attributes for relational algebra, DRC, TRC, and SQL. (DRC By-Name has an inherent syntax for creating named tables with column names identified.)
| <Query_Definition> |
® |
<Query> ; |
|
| |
<Assignment_Statement> ; | |
| <Assignment_Statement> |
® |
Relation_Name := <Query> |
|
| |
Relation_Name ( <Attribute_List> ) := <Query> | |
| <Attribute_List> |
® |
Attribute_Name , <Attribute_List> |
|
| |
Attribute_Name |
The relational algebra is a procedural language with the following assumptions regarding its operators:
|
<Query> |
® |
<Expression> |
|
<Expression> |
® |
Identifier |
|
|
| |
( <Expression> ) |
|
|
| |
<Select_Expr> |
|
|
| |
<Project_Expr> |
|
|
| |
<Binary_Expr> |
|
<Select_Expr> |
® |
select <Condition> ( <Expression> ) |
|
<Project_Expr> |
® |
project <Attributes> ( <Expression> ) |
|
<Binary_Expr> |
® |
( <Expression> ) <Binary_Op> ( <Expression> ) |
|
<Condition> |
® |
<And_Condition> |
|
| |
<And_Condition> or <Condition> | |
|
<And_Condition> |
® |
<Rel_Formula> |
|
|
| |
<Rel_Formula> and <And_Condition> |
|
<Rel_Formula> |
® |
<Operand> <Relational_Op> <Operand> |
|
|
| |
( <Condition> ) |
|
<Binary_Op> |
® |
union |
|
|
| |
njoin |
|
|
| |
product |
|
|
| |
difference |
|
|
| |
intersect |
|
<Attributes> |
® |
Identifier |
|
|
| |
Identifier, <Attributes> |
|
<Operand> |
® |
Identifier |
|
|
| |
Constant |
|
<Relational_Op> |
® |
= |
|
|
| |
> |
|
| |
< | |
|
|
| |
<> |
|
| |
>= | |
|
| |
<= |
The domain relational calculus (DRC) language is a declarative, positional language where variables range over the domain of attributes. Note that constants and anonymous variables (_) may be used within a DRC expression. For example, consider the query that returns the names and salaries of the Database Administrator employees earning more than 35000:
{ LName, FName, Salary |
employee(_, LName, FName,'Database Administrator', Salary) and Salary > 35000};
The interpreter assumes that
{ LName, FName, Salary |
Salary > 35000 and employee(_, LName, FName,'Database Administrator',Salary) };
The rule of thumb for writing safe expressions is to make sure that a variable is bound to a value before it is used, either in a comparison or within a negation.
|
<Query> |
® |
{ <Variables> | <Formula> } |
|
<Formula> |
® |
<And_Formula> |
|
| |
<And_Formula> or <Formula> | |
|
<And_Formula> |
® |
<Sub_Formula> |
|
| |
<Sub_Formula> and <And_Formula> | |
|
<Sub_Formula> |
® |
Identifier ( <Vars_Cons> ) |
|
| |
( <Formula> ) | |
|
| |
not <Sub_Formula> | |
|
| |
<Condition> | |
|
| |
<Quantified_Formula> | |
|
<Quantified_Formula> |
® |
<Quantifier> ( <Formula> ) |
|
| |
<Quantifier> <Quantified_Formula> | |
|
<Quantifier> |
® |
( exists <Variables> ) |
|
| |
( forall <Variables> ) | |
|
<Condition> |
® |
<Operand> <Relational_Op> <Operand> |
|
<Operand> |
® |
Identifier |
|
| |
Constant | |
|
<Variables> |
® |
Identifier |
|
| |
Identifier, <Variables> | |
|
<Vars_Cons> |
® |
Identifier |
|
| |
Identifier, <Vars_Cons> | |
|
| |
Constant | |
|
| |
Constant , <Vars_Cons> | |
|
<Relational_Op> |
® |
= |
|
| |
> | |
|
| |
< | |
|
| |
<> | |
|
| |
>= | |
|
| |
<= |
The DRC By-Name language is a declarative language that references the domain of attributes using the attribute name instead of position. Attributes needed in a query are named and given a variable or constant. Attributes that are not needed in a particular query are left out entirely. The same query that was given under the Domain Relation Calculus BNF is written as follows in DRC By-Name:
dbn1(lname: L, fname: F, salary: S) <-
employee(eSalary: S, eFname: F, eTitle:'Database Administrator', eLname: L)
and S > 35000;
Note that the position of the attributes in the tables do not matter. However, the attribute names MUST match attributes in the given table. Also, DRC By-Name syntax overrides the syntax for creating intermediate tables used in DRC, TRC, relational algebra, and SQL. (The BNF for the intermediate tables was given at the beginning of the Language Assumptions and BNF section.) In the above example, dbn1 will be the name of the intermediate table with column headings: lname, fname, and salary. These column names can be any name the user desires, as long as they start with a lower case letter.
The interpreter assumes that
|
<Query> |
� |
table_name (<Variables>) <– <Formula> |
|
<Formula> |
� |
<And_Formula> |
|
| |
<And_Formula> or <Formula> | |
|
<And_Formula> |
� |
<Sub_Formula> |
|
| |
<Sub_Formula> and <And_Formula> | |
|
<Sub_Formula> |
� |
Schema_Name ( <Vars_Cons> ) |
|
| |
( <Formula> ) | |
|
| |
not <Sub_Formula> | |
|
| |
<Condition> | |
|
| |
<Quantified_Formula> | |
|
<Quantified_Formula> |
� |
<Quantifier> ( <Formula> ) |
|
| |
<Quantifier> <Quantified_Formula> | |
|
<Quantifier> |
� |
( exists <Variables> ) |
|
| |
( forall <Variables> ) | |
|
<Condition> |
� |
<Operand> <Relational_Op> <Operand> |
|
<Operand> |
� |
Identifier |
|
| |
Constant | |
|
<Variables> |
� |
Column_name: Indentifier |
|
| |
Column_name: Identifier, <Variables> | |
|
<Vars_Cons> |
� |
Attribute_name: Identifier |
|
| |
Attribute_name: Identifier, <Vars_Cons> | |
|
| |
Attribute_name: Constant | |
|
| |
Attribute_name: Constant , <Vars_Cons> | |
|
<Relational_Op> |
� |
= |
|
| |
> | |
|
| |
< | |
|
| |
<> | |
|
| |
>= | |
|
| |
<= |
The tuple relational calculus (TRC) language is a declarative language similar to DRC except that variables range over tuples and attributes are referenced using dot notation. The interpreter only evaluates safe TRC expressions. In TRC, this means that the tuple variable must be bound to its associated relation before the values of its attributes can be accessed and before the variable is used within a negation. Here is the TRC version of the query that returns the names and salaries of the female employees earning more than 35000:
{ E.lname, E.fname, E.salary |
employee(E) and E.sex='F' and E.salary>35000 };
The only additional assumption for TRC is a shorthand notation for selecting all attributes associated with a tuple variable. For example, the following shows the result of the above query when all employee attributes are returned:
{ E | employee(E) and E.sex='F' and E.salary>35000 };
|
<Query> |
® |
{ <Vars_Attrs> | <Formula> } |
|
<Formula> |
® |
<And_Formula> |
|
| |
<And_Formula> or <Formula> | |
|
<And_Formula> |
® |
<Sub_Formula> |
|
| |
<Sub_Formula> and <And_Formula> | |
|
<Sub_Formula> |
® |
Identifier ( Variable ) |
|
| |
( <Formula> ) | |
|
| |
not <Sub_Formula> | |
|
| |
<Condition> | |
|
| |
<Quantified_Formula> | |
|
<Quantified_Formula> |
® |
<Quantifier> ( <Formula> ) |
|
| |
<Quantifier> <Quantified_Formula> | |
|
<Quantifier> |
® |
( exists <Variables> ) |
|
| |
( forall <Variables> ) | |
|
<Condition> |
® |
<Operand> <Relational_Op> <Operand> |
|
<Operand> |
® |
Identifier. Identifier |
|
| |
Constant | |
|
<Vars_Attrs> |
® |
Identifier |
|
| |
Identifier, <Vars_Attrs> | |
|
| |
Identifier.Identifier | |
|
| |
Identifier.Identifier, <Vars_Attrs> | |
|
<Variables> |
® |
Identifier |
|
| |
Identifier, <Variables> | |
|
<Relational_Op> |
® |
= |
|
| |
> | |
|
| |
< | |
|
| |
<> | |
|
| |
>= | |
|
| |
<= |
The syntax recognized by the interpreter is the original SQL standard - not SQL-92. In addition to the basic select-from-where query expression, the interpreter handles grouping, aggregation, having, ordering, and nested subqueries. The interpreter, however, has some simplifying assumptions:
For example, consider the query to find the employees earning the maximum salary over the COMPANY database. Although the first SQL query is a valid query in the standard, it is not allowed by the tool. But the query can be evaluated using the second formulation.
1. select ssn, salary from employee where salary = (select max(salary) from employee);2. maxsalary(maxSal) := select max(salary) from employee; select ssn, salary from employee, maxsalary where salary=maxSal;
Consider the query to find the employees who have taken a database course over the EMPLOYEE TRAINING database. The first SQL query is valid by the standard, it is not allowed by the tool. This query can be evaluated using the second version.
1. select distinct EmpDB.eID, EmpDB.eLast, EmpDB.eFirst, EmpDB.eTitle from (employee natural join (takes natural join dbCourse)) as EmpDB;2. select distinct E.eID, E.eLast, E.eFirst, E.eTitle from (employee E natural join (takes T natural join dbCourse d));
|
<Query> |
® |
<Query_Term> |
|
|
| |
<Query_Term> union [all] <Query> |
|
|
| |
<Query_Term> intersect <Query> |
|
|
| |
<Query_Term> except <Query> |
|
<Query_Term> |
® |
<Sub_Query> |
|
|
| |
(<Query>) |
|
<Sub_Query> |
® |
select <Select_Vars> from <Expression> |
|
|
|
[<Group_Clause> [<Having_Clause>] ] [<Order_Clause>] |
|
<Select_Vars> |
® |
* |
|
|
| |
[distinct] <Scalar_Varlist> |
|
|
| |
[all] <Scalar_Varlist> |
|
<Scalar_Varlist> |
® |
<Scalar_Vars>[[as] columnName ] [, <Scalar_Varlist>] |
|
<Scalar_Vars> |
® |
<Term> |
|
|
| |
<Term> - <Scalar_Var> |
|
|
| |
<Term> + <Scalar_Var> |
|
<Term> |
® |
<Factor> |
|
|
| |
<Factor> / <Term> |
|
|
| |
<Factor> * <Term> |
|
<Factor> |
® |
[+ | -] <Primary> |
|
<Primary> |
® |
<Atom> |
|
|
| |
<Aggregation_Var> |
|
|
| |
(<Scalar_Var>) |
|
<Atom> |
® |
Constant |
|
|
| |
Identifier |
|
<Aggregation_Var> |
® |
count(*) |
|
|
| |
count(distinct <Simple_Var>) |
|
|
| |
<Function> ([distinct] <Simple_Var>) |
|
|
| |
<Function> ([all] <Simple_Var>) |
|
<Function> |
® |
min |
|
|
| |
max |
|
|
| |
avg |
|
|
| |
sum |
|
<Simple_Var> |
® |
Identifier |
|
|
| |
Identifier.Identifier |
|
<Expression> |
® |
<Relation_List> [where <Search_Condition>] |
|
<Relation_List> |
® |
<Table_Reference> [, <Relation_List>] |
|
<Table_Reference> |
® |
Identifier |
|
|
| |
Identifier Alias |
|
|
| |
<Join_Table_Expression> |
|
<Join_Table_Expression> |
® |
<Table_Reference> natural join <Table_Reference> |
|
|
| |
<Table_Reference> join <Table_Reference> on <Search_Condition> |
|
|
| |
<(Join_Table_Expression)> |
|
<Search_Condition> |
® |
<Boolean_Term> |
|
|
| |
<Boolean_Term> or <Search_Condition> |
|
<Boolean_Term> |
® |
<Boolean_Factor> |
|
|
| |
<Boolean_Factor> and <Boolean_Term> |
|
<Boolean_Factor> |
® |
[not] <Boolean_Primary> |
|
<Boolean_Primary> |
® |
<Predicate> |
|
|
| |
(<Search_Condition>) |
|
<Predicate> |
® |
<Exists_Predicate> |
|
|
| |
<In_Predicate> |
|
|
| |
<Comparison_Predicate> |
|
<Exists_Predicate> |
® |
exists (<Simple_Subquery>) |
|
<In_Predicate> |
® |
<Simple_Var> [not] in (<Simple_Subquery>) |
|
|
| |
<Simple_Var> [not] in (<Atom_List>) |
|
<Atom_List> |
® |
<Atom> [, <Atom_List>] |
|
<Comparison_Predicate> |
® |
<Simple_Var><Comparison><Simple_Var> |
|
|
| |
<Simple_Var><Comparison><Simple_Subquery> |
|
<Comparison> |
® |
= |
|
|
| |
<> |
|
|
| |
< |
|
|
| |
> |
|
|
| |
<= |
|
|
| |
>= |
|
<Group_Clause> |
® |
group by <Group_Varlist> |
|
<Group_Varlist> |
® |
<Simple_Var> [, <Group_Varlist>] |
|
<Having_Clause> |
® |
having <Having_Condition> |
|
<Having_Condition> |
® |
<Having_Term> |
|
|
| |
<Having_Term> or <Having_Condition> |
|
<Having_Term> |
® |
<Having_Factor> |
|
|
| |
<Having_Factor> and <Having_Term> |
|
<Having_Factor> |
® |
[not] <Having_Primary> |
|
<Having_Primary> |
® |
<Having_Compare> |
|
|
| |
(<Having_Condition>) |
|
<Having_Compare> |
® |
<Aggregation_Var><Comparison><Aggregation_Var> |
|
<Order_Clause> |
® |
order by <Order_Varlist> [asc | desc] |
|
<Order_Varlist> |
® |
<Order_Var> [, <Order_Varlist>] |
|
<Order_Var> |
® |
<Simple_Var> |
|
|
| |
Constant |
|
<Simple_Subquery> |
® |
<Sub_Query> without <Aggregation_Var>, <Group_Clause>, or <Order_Clause> |
WinRDBI is the realization of the efforts of several students at ASU: Eric Eckert, Changguan Fan, April Granroth, Isabel Hankes, Chien-Ho Ho, Ana Hun, Sonia Jain, Spencer Pearson, Kevin Piscator, Rick Rankin, Sarah Simons, and Adrian Sylvester.